An introduction to MUDROD ranking algorithm
Posted 2018-04-23 by Lewis John McGibbney
When a user types some keywords into a search engine, there are typically hundreds, or even thousands of datasets related to the given query. Although high level of recall can be useful in some cases, the user is only interested in a much smaller subset. Current search engines in most geospatial data portals tend to induce end users to focus on one single data characteristic/feature dimension (e.g., spatial resolution), which often results in less than optimal user experience (Ghose, Ipeirotis, and Li 2012).
To overcome this fundamental ranking problem, we therefore 1) identify a number of ranking features of geospatial data to represent users’ multidimensional preferences by considering semantics, user behaviour, spatial similarity, and static dataset metadata attributes; 2) apply machine learning method to automatically learn a function from a training set capable of ranking geospatial data according to the ranking features.
Within the ranking process, each query will be associated with a set of data, and each data can be represented as a feature vector. Eleven features listed below are identified by considering user behaviour, query-text match and examining common geospatial metadata attributes.
| Query-dependent features |
|---|
| Lucene relevance score |
| Semantic popularity |
| Spatial Similarity |
| Query-dependent features |
|---|
| Release date |
| Processing level |
| Version number |
| Spatial resolution |
| Temporal resolution |
| All-time popularity |
| Monthly popularity |
| User popularity |
RankSVM, one of the well-recognized learning approach is selected to learn feature weights to rank search results. In RankSVM (Joachims 2002), ranking is transformed into a pairwise classification task in which a classifier is trained to predict the ranking order of data pairs.
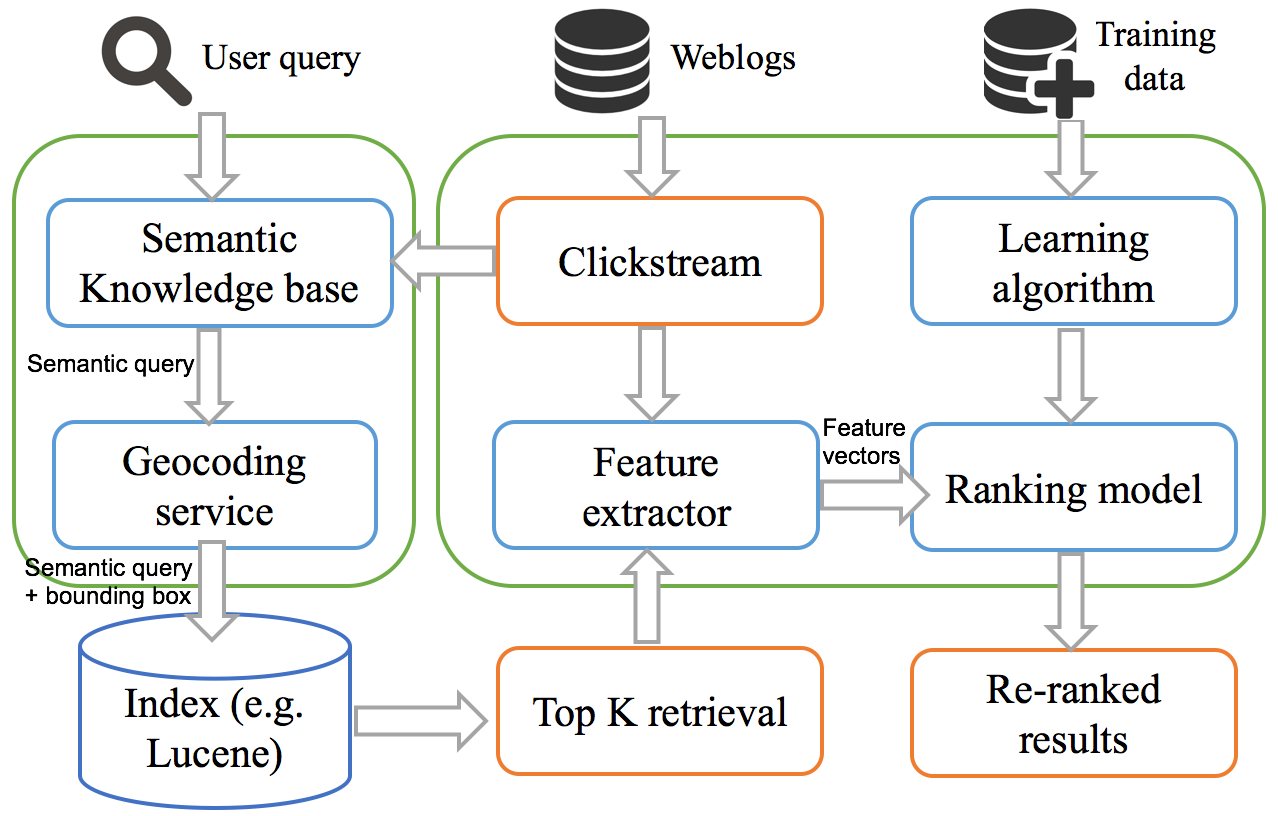 Figure 1. System workflow and architecture
Figure 1. System workflow and architecture
The proposed architecture primarily consists of six components comprising semantic knowledge base, geocoding service, search index, feature extractor, learning algorithm, and ranking model respectively (Figure 1). When a user submits a query, it is then converted into a semantic query and a geographical bounding box by the semantic knowledge base and geocoding service. The search index would then return the top K results for the semantic query combined with the bounding box. After that, feature extractor would extract the ranking features for each of the search results, including the semantic click score. Once all the features are prepared, the top K results would then be put into a pre-trained ranking model, which would finally re-rank the top K retrieval. As the index in this architecture can be any Lucene-based software, it enables the loosely coupled software structure of a data portal and avoids the cost of replacing the existing system.
Reference:
-
Ghose, Anindya, Panagiotis G Ipeirotis, and Beibei Li. 2012. “Designing ranking systems for hotels on travel search engines by mining user-generated and crowdsourced content.” Marketing Science 31 (3):493-520.
-
Joachims, Thorsten. 2002. Optimizing search engines using clickthrough data. Paper presented at the Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining.