An introduction to MUDROD vocabulary similarity calculation algorithm
Posted 2018-04-23 by Lewis John McGibbney
Big geospatial data have been produced, archived and made available online, but finding the right data for scientific research and decision-support applications remains a significant challenge. A long-standing problem in data discovery is how to locate, assimilate and utilize the semantic context for a given query. Most of past research in geospatial domain attempts to solve this problem through two approaches: 1) building a domain-specific ontology manually; 2) discovering semantic relationship through dataset metadata automatically using machine learning techniques. The former contains rich expert knowledge, but it is static, costly, and labour intensive, while the latter is automatic, it is prone to noise.
An emerging trend in information science is to take advantage of large-scale user search history, which is dynamic but contains user and crawler generated noise. Leveraging the benefits of all of these three approaches and avoiding their weaknesses, a novel approach is proposed in this article to 1) discover vocabulary semantic relationship from user clickstream; 2) refine the similarity calculation methods from existing ontology; 3) integrate the results of ontology, metadata, user search history and clickstream analysis to better determine the semantic relationship.
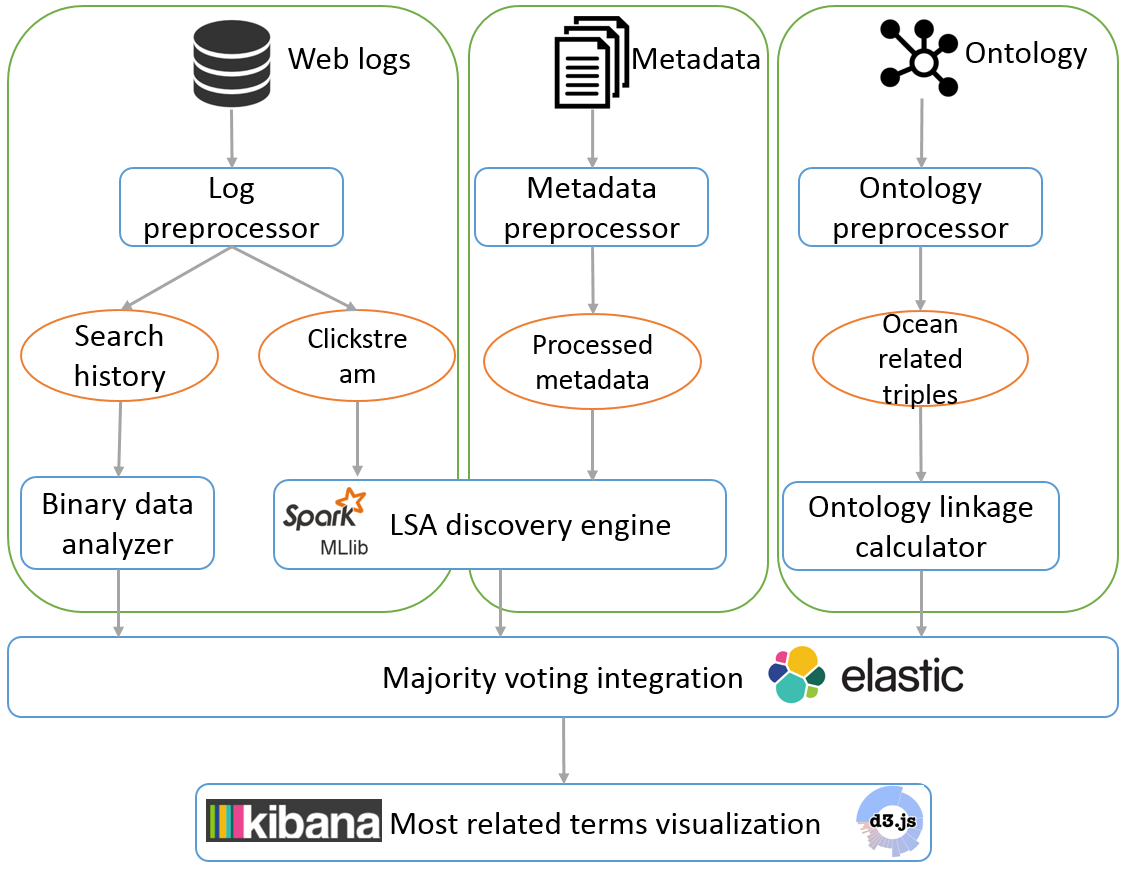 Figure 1. System workflow and architecture
Figure 1. System workflow and architecture
The system starts by pre-processing raw web logs, metadata, and ontology (Figure 1 ). After pre-processing step, search history and clickstream data are extracted from raw logs, selected properties are extracted from metadata, and ocean-related triples are extracted from the SWEET ontology. These four types of processed data are then put into their corresponding processer as discussed in the last section. Once all the processers finish their jobs, the results of different methods are integrated to produce a final most related terms list.