Blog
V1.4.0 Release
Posted 2024-11-04 by Riley Kuttruff
The SDAP community is pleased to announce our latest release of Apache SDAP, version 1.4.0. This release includes introductory support for 3-dimensional data, with a reference implementation for visualizing TomoSAR (3-dimensional synthetic aperture radar tomography). Other 3D use cases could include oceanographic modelling at different depths or atmospheric measurements at different elevations/pressures.
Instructions for building Docker images from the source release
Instructions for deploying locally to test
Release notes:
Resources:
- Github:
- Jira
- Mailing list
V1.3.0 Release
Posted 2024-07-08 by Riley Kuttruff
The SDAP community is pleased to announce our latest release of Apache SDAP, version 1.3.0, our first release as a Top-Level Project!
Instructions for building Docker images from the source release
Instructions for deploying locally to test
Release notes:
Resources:
- Github:
- Jira
- Mailing list
Sdap Graduation
Posted 2024-04-17 by Riley Kuttruff
The SDAP community is pleased to announce we have graduated the Apache Incubator to become a Top-Level Project!
This is a significant accomplishment for all who have worked on SDAP and the SDAP PMC would like to thank everyone who has contributed to helping us achieve this goal. Thank you!
V1.2.0 Release
Posted 2024-03-15 by Stepheny Perez
The SDAP community is pleased to announce our latest release of Apache SDAP (incubating), version 1.2.0!
Instructions for building Docker images from the source release
Instructions for deploying locally to test
Release notes:
Resources:
- Github:
- Jira
- Mailing list
New SDAP Logo
Posted 2023-11-29 by Stepheny Perez
The SDAP community is pleased to announce our new logo!
 Figure 1. New SDAP Logo
Figure 1. New SDAP Logo
V1.0.0 Release
Posted 2023-01-20 by Riley Kuttruff
The SDAP community is pleased to announce our first release of Apache SDAP (incubating), version 1.0.0!
Instructions for building Docker images from the source release
Instructions for deploying locally to test
Release notes:
Resources:
- Github:
- Jira
- Mailing list
An introduction to MUDROD vocabulary similarity calculation algorithm
Posted 2018-04-23 by Lewis John McGibbney
Big geospatial data have been produced, archived and made available online, but finding the right data for scientific research and decision-support applications remains a significant challenge. A long-standing problem in data discovery is how to locate, assimilate and utilize the semantic context for a given query. Most of past research in geospatial domain attempts to solve this problem through two approaches: 1) building a domain-specific ontology manually; 2) discovering semantic relationship through dataset metadata automatically using machine learning techniques. The former contains rich expert knowledge, but it is static, costly, and labour intensive, while the latter is automatic, it is prone to noise.
An emerging trend in information science is to take advantage of large-scale user search history, which is dynamic but contains user and crawler generated noise. Leveraging the benefits of all of these three approaches and avoiding their weaknesses, a novel approach is proposed in this article to 1) discover vocabulary semantic relationship from user clickstream; 2) refine the similarity calculation methods from existing ontology; 3) integrate the results of ontology, metadata, user search history and clickstream analysis to better determine the semantic relationship.
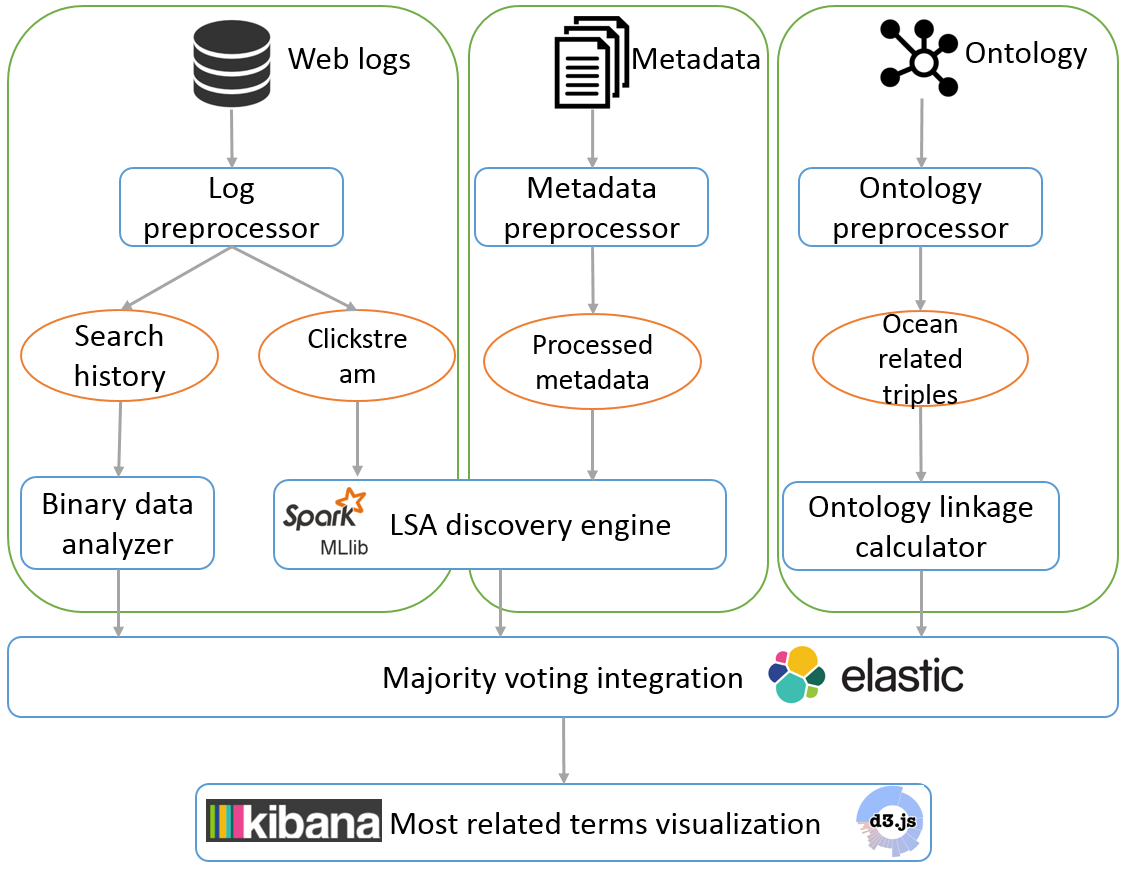 Figure 1. System workflow and architecture
Figure 1. System workflow and architecture
The system starts by pre-processing raw web logs, metadata, and ontology (Figure 1 ). After pre-processing step, search history and clickstream data are extracted from raw logs, selected properties are extracted from metadata, and ocean-related triples are extracted from the SWEET ontology. These four types of processed data are then put into their corresponding processer as discussed in the last section. Once all the processers finish their jobs, the results of different methods are integrated to produce a final most related terms list.
An introduction to MUDROD recommendation algorithm
Posted 2018-04-23 by Lewis John McGibbney
With the recent advances in remote sensing satellites and other sensors, geographic datasets have been growing faster than ever. In response, a number of Spatial Data Infrastructure (SDI) components (e.g. catalogues and portals) have been developed to archive and made those datasets available online. However, finding the right data for scientific research and application development is still a challenge due to the lack of data relevancy information.
Recommendation has become extremely common in recent years and are utilized in a variety of areas to help users quickly find useful information. We propose a recommendation system to improve geographic data discovery by mining and utilizing metadata and usage logs. Metadata abstracts are processed with natural language processing methods to find semantic relationship between metadata. Metadata variables are used to calculate spatial and temporal similarity between metadata. In addition, portal logs are analysed to introduce user preference.
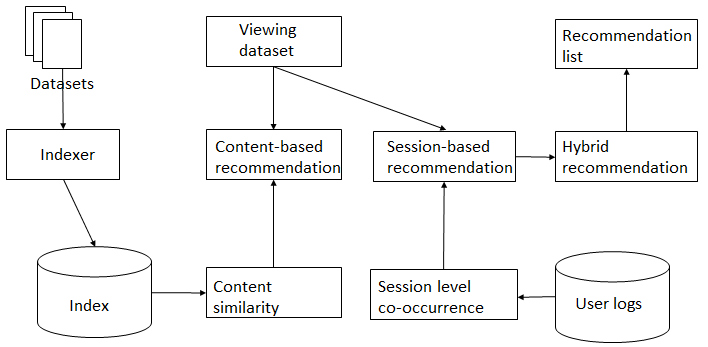 Figure 1. Recommendation workflow
Figure 1. Recommendation workflow
The system starts by pre-processing raw web logs and metadata (Figure 1). After pre-processing step, sessions are reconstructed from raw web logs and then used to calculate session-based metadata similarity. Metadata are harvested from PO.DAAC web service APIs. Metadata variable values are then converted to value using the united unit to calculate metadata content similarity. Elasticsearch is used to store all of the above similarities. Once a user views a metadata record, the system finds the top-k related metadata with a hybrid recommendation methodology. The hybrid recommendation module integrates results from content-based recommendation and session-based recommendation methods and ranks the final recommendation list in a descending order of similarity.
An introduction to MUDROD ranking algorithm
Posted 2018-04-23 by Lewis John McGibbney
When a user types some keywords into a search engine, there are typically hundreds, or even thousands of datasets related to the given query. Although high level of recall can be useful in some cases, the user is only interested in a much smaller subset. Current search engines in most geospatial data portals tend to induce end users to focus on one single data characteristic/feature dimension (e.g., spatial resolution), which often results in less than optimal user experience (Ghose, Ipeirotis, and Li 2012).
To overcome this fundamental ranking problem, we therefore 1) identify a number of ranking features of geospatial data to represent users’ multidimensional preferences by considering semantics, user behaviour, spatial similarity, and static dataset metadata attributes; 2) apply machine learning method to automatically learn a function from a training set capable of ranking geospatial data according to the ranking features.
Within the ranking process, each query will be associated with a set of data, and each data can be represented as a feature vector. Eleven features listed below are identified by considering user behaviour, query-text match and examining common geospatial metadata attributes.
| Query-dependent features |
|---|
| Lucene relevance score |
| Semantic popularity |
| Spatial Similarity |
| Query-dependent features |
|---|
| Release date |
| Processing level |
| Version number |
| Spatial resolution |
| Temporal resolution |
| All-time popularity |
| Monthly popularity |
| User popularity |
RankSVM, one of the well-recognized learning approach is selected to learn feature weights to rank search results. In RankSVM (Joachims 2002), ranking is transformed into a pairwise classification task in which a classifier is trained to predict the ranking order of data pairs.
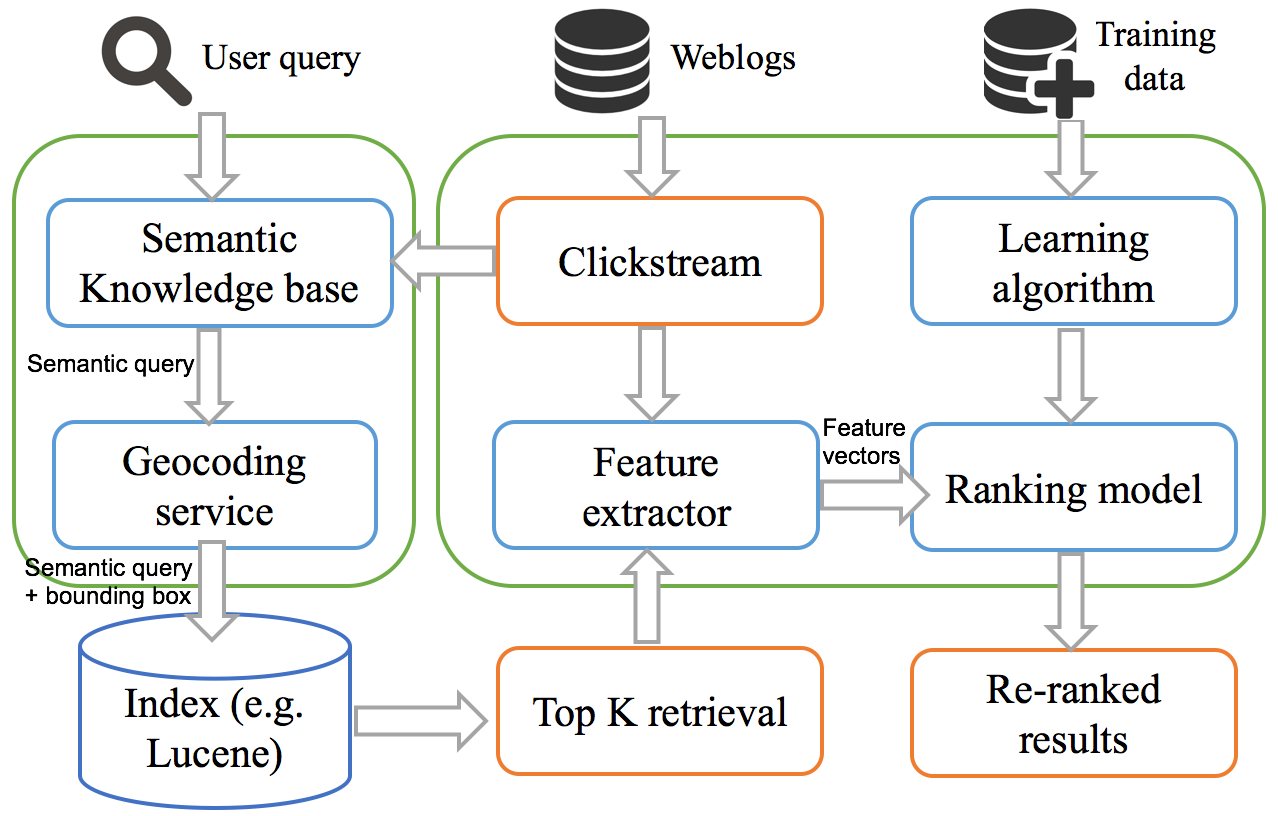 Figure 1. System workflow and architecture
Figure 1. System workflow and architecture
The proposed architecture primarily consists of six components comprising semantic knowledge base, geocoding service, search index, feature extractor, learning algorithm, and ranking model respectively (Figure 1). When a user submits a query, it is then converted into a semantic query and a geographical bounding box by the semantic knowledge base and geocoding service. The search index would then return the top K results for the semantic query combined with the bounding box. After that, feature extractor would extract the ranking features for each of the search results, including the semantic click score. Once all the features are prepared, the top K results would then be put into a pre-trained ranking model, which would finally re-rank the top K retrieval. As the index in this architecture can be any Lucene-based software, it enables the loosely coupled software structure of a data portal and avoids the cost of replacing the existing system.
Reference:
-
Ghose, Anindya, Panagiotis G Ipeirotis, and Beibei Li. 2012. “Designing ranking systems for hotels on travel search engines by mining user-generated and crowdsourced content.” Marketing Science 31 (3):493-520.
-
Joachims, Thorsten. 2002. Optimizing search engines using clickthrough data. Paper presented at the Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining.